解析技术
形式文法
定义:

分类:
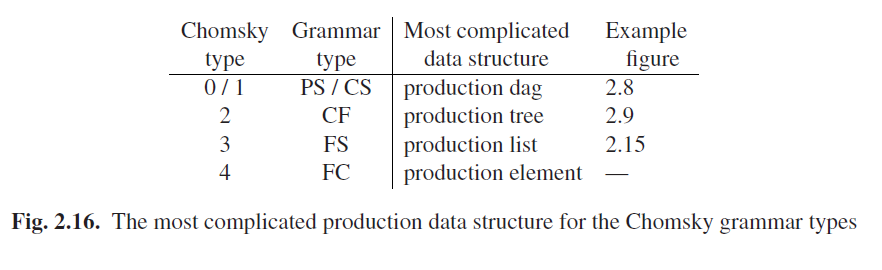
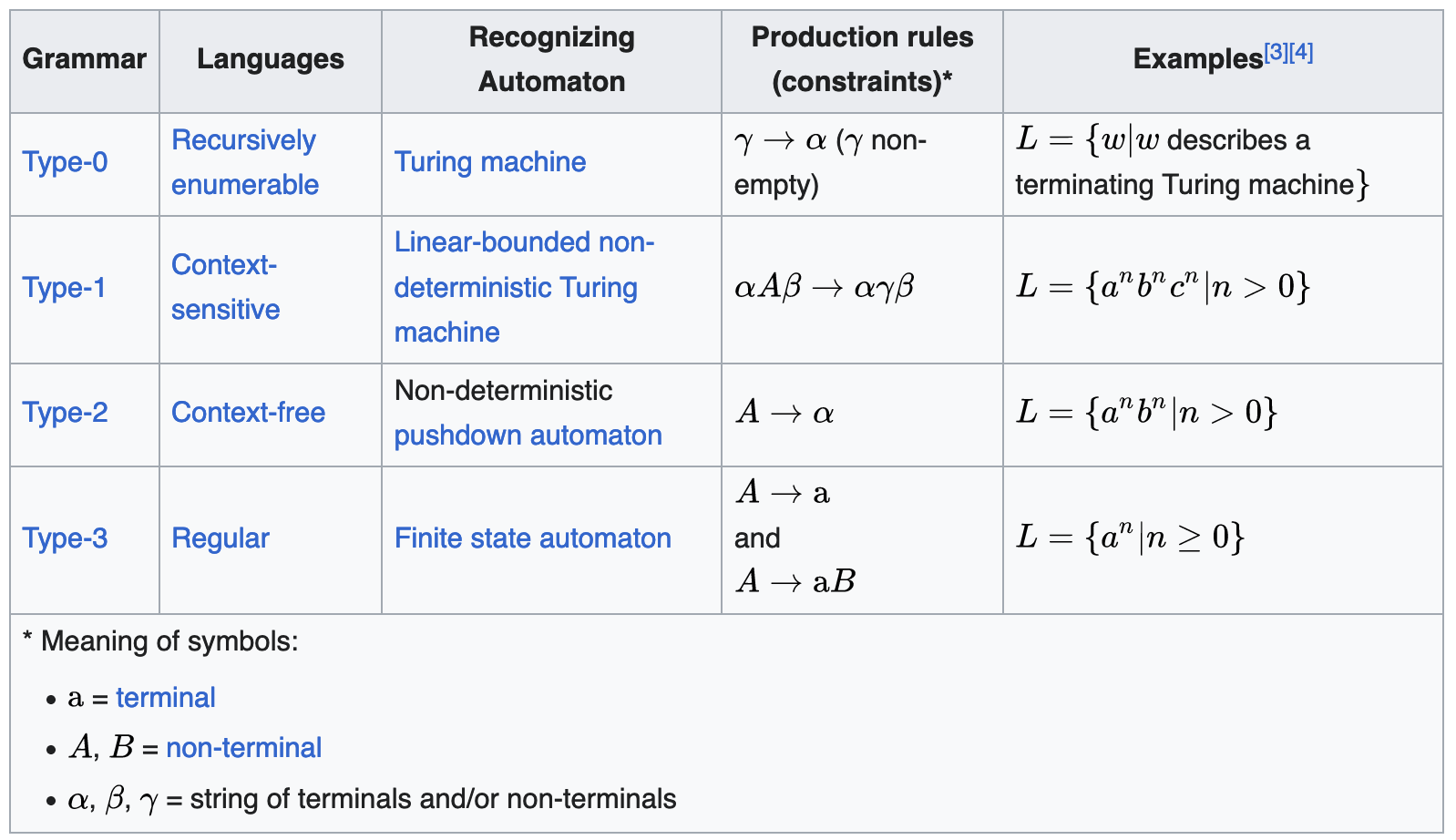
表示方法:
- BNF
- PEG
自动机

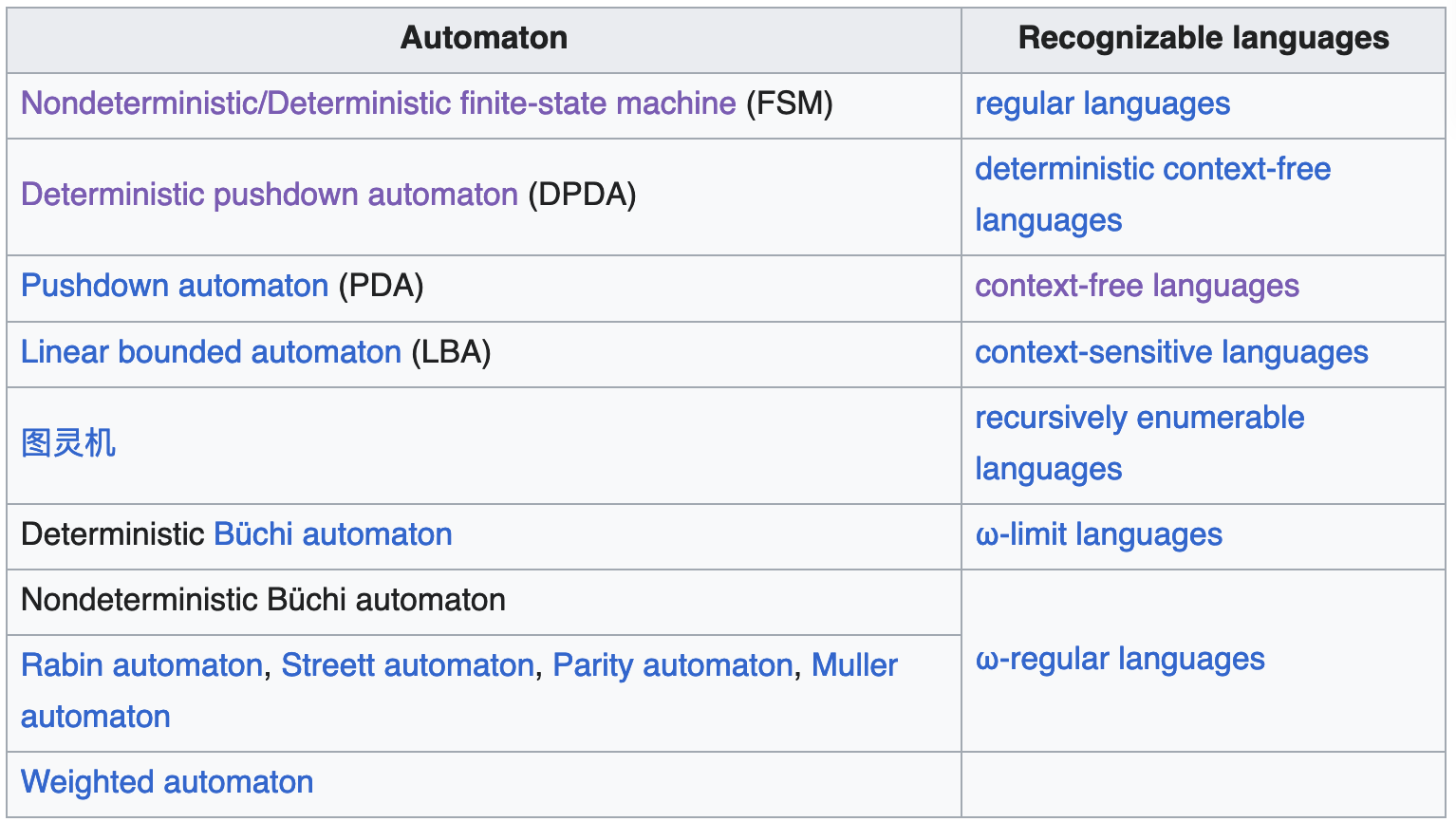
解析
- 自顶向下
- 自底向上
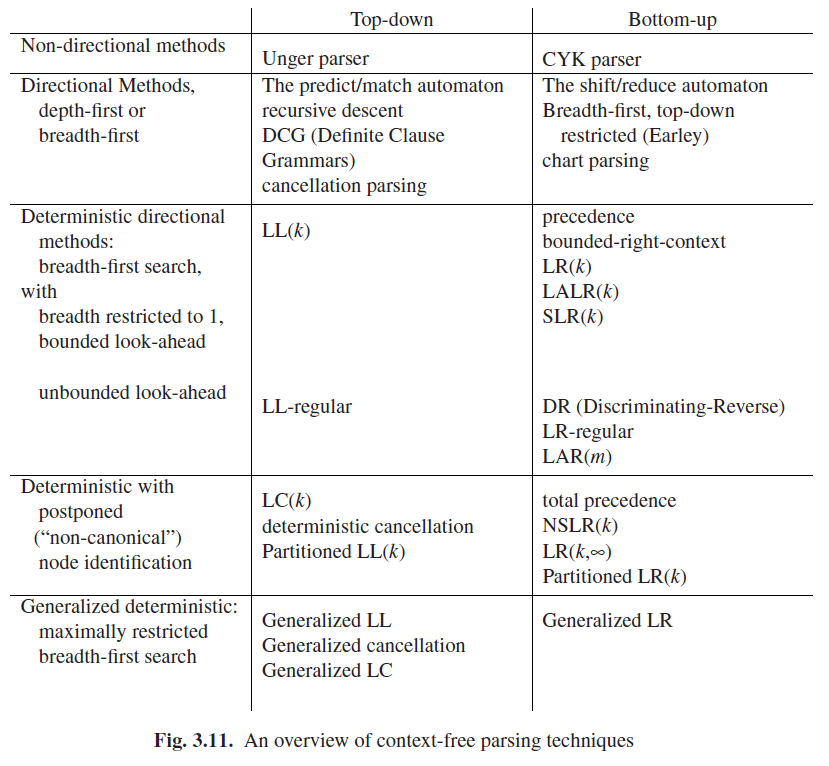
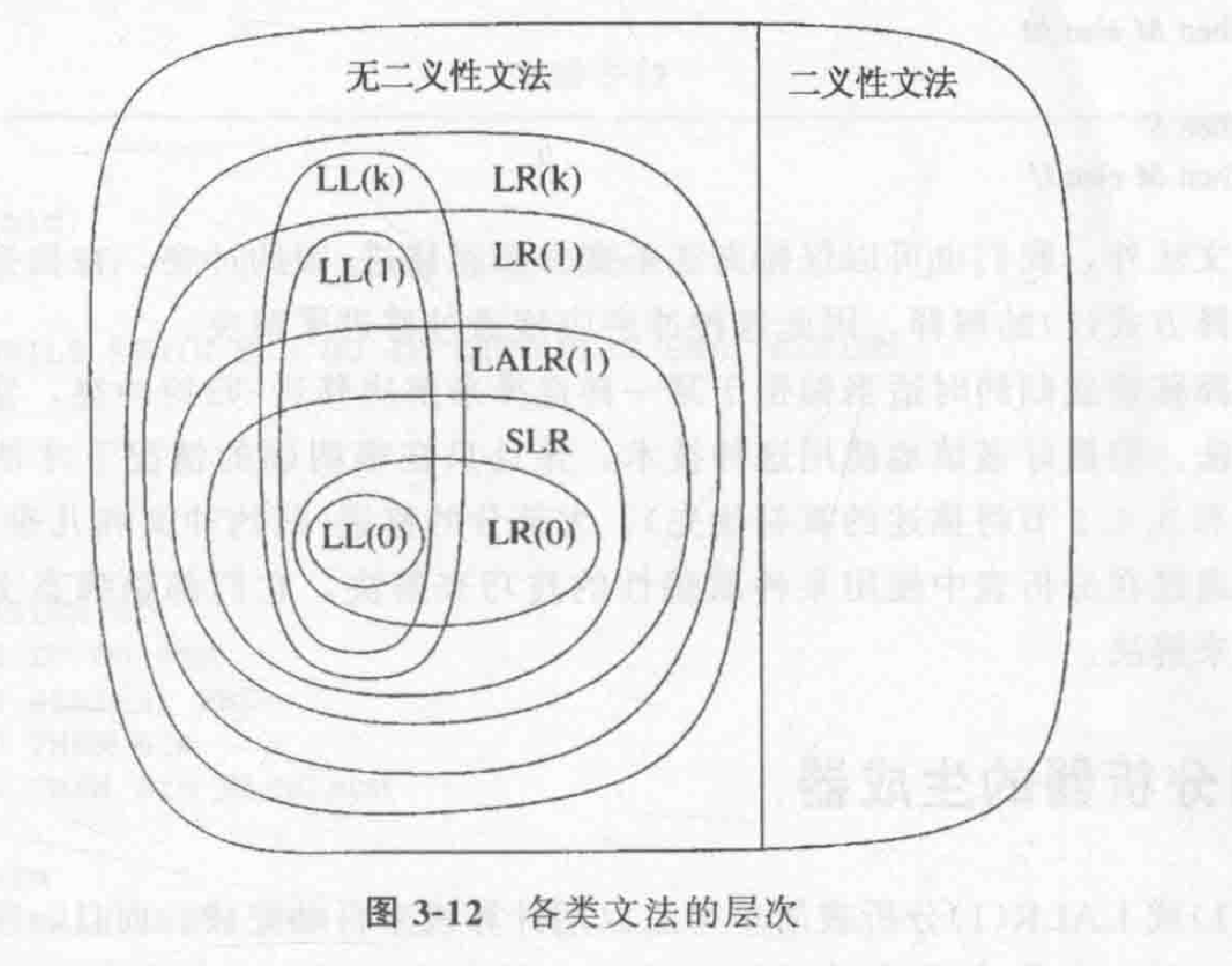
常见 Parser Generator:
- Lex & Yacc
- Flex & Bison
- PLY
- Jison
- Clojure/instaparse
- Rust/Pest
- Parsec
- ANTLR4
实战
import re
# 定义词法单元的正则表达式模式
token_patterns = [
('NUMBER', r'\d+(\.\d+)?'), # 匹配数字
('PLUS', r'\+'), # 匹配加号
('MINUS', r'-'), # 匹配减号
('MULTIPLY', r'\*'), # 匹配乘号
('DIVIDE', r'/'), # 匹配除号
('LPAREN', r'\('), # 匹配左括号
('RPAREN', r'\)'), # 匹配右括号
('WHITESPACE', r'\s+') # 匹配空白字符
]
# 定义一个函数来进行词法分析
def lexer(expression):
tokens = []
pos = 0
while pos < len(expression):
match = None
# 尝试匹配每个正则表达式模式
for token_type, pattern in token_patterns:
regex = re.compile(pattern)
match = regex.match(expression, pos)
if match:
# 如果匹配成功,将匹配到的词法单元加入到tokens列表中
value = match.group(0)
if token_type != 'WHITESPACE':
tokens.append((token_type, value))
pos = match.end(0)
break
# 如果没有匹配到任何模式,说明输入表达式存在非法字符
if not match:
raise ValueError(f"Invalid character: {expression[pos]}")
return tokens
# 测试词法分析器
expression = "3.14 + 2 * (4 - 1)"
tokens = lexer(expression)
for token_type, value in tokens:
print(f"Token: {token_type}, Value: {value}")
# 定义一个函数来进行语法分析
def parser(tokens):
pos = 0
# 辅助函数,用于解析数字
def parse_number():
nonlocal pos
token_type, value = tokens[pos]
if token_type == 'NUMBER':
pos += 1
return float(value)
else:
raise ValueError(f"Expected NUMBER, but got {token_type}")
# 辅助函数,用于解析乘法和除法运算
def parse_term():
nonlocal pos
left = parse_factor()
while pos < len(tokens):
token_type, value = tokens[pos]
if token_type == 'MULTIPLY':
pos += 1
right = parse_factor()
left *= right
elif token_type == 'DIVIDE':
pos += 1
right = parse_factor()
left /= right
else:
break
return left
# 辅助函数,用于解析加法和减法运算
def parse_expression():
nonlocal pos
left = parse_term()
while pos < len(tokens):
token_type, value = tokens[pos]
if token_type == 'PLUS':
pos += 1
right = parse_term()
left += right
elif token_type == 'MINUS':
pos += 1
right = parse_term()
left -= right
else:
break
return left
# 辅助函数,用于解析括号表达式
def parse_factor():
nonlocal pos
token_type, value = tokens[pos]
if token_type == 'LPAREN':
pos += 1
result = parse_expression()
if pos >= len(tokens) or tokens[pos][0] != 'RPAREN':
raise ValueError("Missing closing parenthesis")
pos += 1
return result
else:
return parse_number()
# 开始进行语法分析
result = parse_expression()
# 检查是否处理完所有的词法单元
if pos < len(tokens):
raise ValueError("Unexpected token")
return result
# 测试表达式解析器
expression = "3.14 + 2 * (4 - 1)"
tokens = lexer(expression)
result = parser(tokens)
print(f"Result: {result}")
import ply.lex as lex
import ply.yacc as yacc
# 词法分析器
tokens = (
'NUMBER',
'PLUS',
'MINUS',
'MULTIPLY',
'DIVIDE',
'LPAREN',
'RPAREN',
)
t_PLUS = r'\+'
t_MINUS = r'-'
t_MULTIPLY = r'\*'
t_DIVIDE = r'/'
t_LPAREN = r'\('
t_RPAREN = r'\)'
def t_NUMBER(t):
r'\d+(\.\d+)?'
t.value = float(t.value)
return t
t_ignore = ' \t'
def t_error(t):
print(f"Invalid character: {t.value[0]}")
t.lexer.skip(1)
lexer = lex.lex()
# 语法分析器
precedence = (
('left', 'PLUS', 'MINUS'),
('left', 'MULTIPLY', 'DIVIDE'),
)
def p_expression(p):
'''
expression : expression PLUS expression
| expression MINUS expression
| expression MULTIPLY expression
| expression DIVIDE expression
| LPAREN expression RPAREN
| NUMBER
'''
if len(p) == 2:
p[0] = p[1]
elif p[1] == '(':
p[0] = p[2]
else:
if p[2] == '+':
p[0] = p[1] + p[3]
elif p[2] == '-':
p[0] = p[1] - p[3]
elif p[2] == '*':
p[0] = p[1] * p[3]
elif p[2] == '/':
p[0] = p[1] / p[3]
def p_error(p):
print("Syntax error")
parser = yacc.yacc()
# 测试计算器
while True:
try:
expression = input("请输入表达式:")
result = parser.parse(expression)
print(f"计算结果:{result}")
except EOFError:
break